Kubernetes Aggregation Metrics
kubernetes and prometheus
최근 kubernetes에서 metric을 관리하는 것중 가장 유명한 것은 prometheus라고 할 수 있습니다. metric 관리방법으로 heapster를 사용할때 까지는 influxdb를 많이 사용하는 추세 였으나 앞으로 대채될 metrics-server는 현재 in-memory sink밖에 없어서 우선 기존에 influxdb를 사용하던것을 많이 안쓰게 될것 같습니다. 더욱이 custom metric들에 대한 예제들이 prometheus로 제공되고 있어서 prometheus로 metric관리가 통합될것으로 기대하고 있습니다.
이러한 prometheus로 kubernetes metric들을 수집하는 것은 대체로 크게 2가지 케이스 입니다.
- application 들의 metric 수집
- container 단위 metric 수집
오늘 이야기하고자 하는 주제는 2번과 같이 단위 container들로 수집된 metric들을 kubernetes 안에 pod들로 모아주고 이 pod들의 metric을 aggregation 하여 daemonset, replicaset, deployment, statefulset 과 같은 단위로 데이터를 보여줄 수 있도록 하기 위한 방법입니다.
grafana dashboard를 통해 살펴보는 기존 방법들
실제 grafana dashboard들을 참고하면 마땅히 위와 같은 방식으로 aggregation한 대쉬보드를 많이 찾을 수가 없을 것입니다. 아래는 grafana dashboard 중에서 kubernetes와 관련된 그래프들을 중 다운로드 수가 높은 순으로 정렬해봤습니다. 이중 높은 순위 10개가 아래와 같습니다.
$ (echo -e "Download@Link@Name" ; \
curl -s 'https://grafana.com/api/dashboards?orderBy=name&includeLogo=1&page=1&pageSize=100000&filter=kubernetes' | \
jq -cr '.items | sort_by(.downloads)[] | ((.downloads | tostring) + "@https://grafana.com/dashboards/" + (.id | tostring) + "@" + (.name))' | tail -n10) | \
column -s '@' -t
Download Link Name
4603 https://grafana.com/dashboards/747 Kubernetes Pod Metrics
5430 https://grafana.com/dashboards/162 Kubernetes cluster monitoring (via Prometheus)
5904 https://grafana.com/dashboards/5303 Kubernetes Deployment (Prometheus)
6215 https://grafana.com/dashboards/3320 Kubernetes Node Exporter Full
6288 https://grafana.com/dashboards/3131 Kubernetes All Nodes
6466 https://grafana.com/dashboards/3119 Kubernetes cluster monitoring (via Prometheus)
7760 https://grafana.com/dashboards/5309 Kubernetes Capacity (Prometheus)
10884 https://grafana.com/dashboards/315 Kubernetes cluster monitoring (via Prometheus)
12866 https://grafana.com/dashboards/6663 Kubernetes pod and cluster monitoring (via Prometheus)
29231 https://grafana.com/dashboards/1621 Kubernetes cluster monitoring (via Prometheus)
이런 데이터를 몇개 보시면 알겠지만 대부분 node 혹은 pod의 이름으로만 검색해서 보도록 되어 있습니다.
예를 들어 아래와 같이 node와 pod 이름으로 검색해서 보던가
Kubernetes Pod Metrics
혹은 아래와 같이 node를 선택하고 그 안에서 pod들을 보도록 되어 있습니다.
Kubernetes cluster monitoring (via Prometheus)
하지만 실제 우리가 kubernetes를 운영하다보면 kubernetes안의 object중 daemonset, statefulset, deployment 와 같은 단위로 선택해서 보고 싶은 경우들이 생기기에 이런 dashboard 만으로 부족하다는걸 알 수 있습니다.
string partial match를 이용한 방법들
이런 경우 일반적으로 현재까지는 container이름들의 앞부분이 일치하는 것을 이용하여 이런 것을 string partial match 하여 해당 pod이 해당 deployment 들에 포함되는 것을 알아내는 식으로 구현 했습니다.
예를 들면 calico-node daemonset의 pod 이름들은 calico-node-xxxxx의 패턴이기 때문에 calico-node-.* 와 같은 regrex로 match를 유도하는 것입니다. 예를 들면 아래와 같습니다.
rate(container_cpu_usage_seconds_total{namespace="$namespace",pod_name=~"$daemonset.*"}[1m])
실제 dashboard 들은 아래와 같은 것들을 참고해보면 이런 방식으로 많이 구현함을 알 수 있습니다. Kubernetes StatefulSets (Prometheus)
하지만 이런 방법들은 정확하지 않고 좀 더 확실한 방법이 없나 찾게 됩니다. 왜냐하면 예를들어 만약 calico-node-test 와 같이 앞부분이 일치하는 다른 daemonset이 있다면 저런 regrex로 match 시키기 어려워 지기 때문입니다.
label의 partial match를 이용한 방법들
아래 링크들과 같이 pod들의 label이 부분 일치하는것들을 이용해서 방법론들이 있었습니다. 이런 aggregation 하는 글들을 적용하면 정확한 pod을 찾아내기 위해서는 label을 열심히 준비해야 하는등 실제 상황에서는 좀 쓰기 불편한것들이 있었습니다.
Kubernetes PromQL (Prometheus Query Language) CPU aggregation walkthrough
Use Prometheus Vector Matching to get Kubernetes Utilization across any Pod Label
그래서 이런 부분 일치 시키는 방법보다 kubernetes가 실제 pod을 관리하는 방법과 가장 유사하게 수집이 되면 좋겠다고 생각할 수 있습니다.
prometheus의 pod metric을 위한 raw 데이터
우선 pod들의 데이터를 aggregation하기 전에 container 단위로 수집되는 데이터들을 pod의 데이터로 환산하기 위한 방법을 설명합니다.
예를 들어 helm chart default 값으로 labeling 값들이 구성되어 있고 prometheus에서 pod 이름으로 예를 들어 데이터를 아래와 같이 수집한다고 했을때,
container_cpu_usage_seconds_total{namespace="kube-system",pod_name="calico-node-xxxxx"}
실제 확인되는 데이터들은 아래와 같습니다. 한 pod이지만 아래와 같이 3개의 데이터로 구성이 되어있는데 1개의 데이터가 아닌 이유는 cadvisor가 container단위로 수집하기 때문입니다. 수집하는 cadvisor 입장에서는 수집되는 데이터는 container기준으로만 수집이 되기 때문에 아래와 같습니다. 아래 calico-node 같은 경우 1개의 pause container와 2개의 conatiner(side car)로 구성되어 있기 때문에 3개 입니다.
container_cpu_usage_seconds_total{
beta_kubernetes_io_arch="amd64",
beta_kubernetes_io_fluentd_ds_ready="true",
beta_kubernetes_io_os="linux",
container_name="POD",
cpu="total",
id="/system.slice/docker-9e11fe23188ab8df11e6695fd56567df63ff7d0709b0be1d892d5f32283a61af.scope",
image="k8s.gcr.io/pause-amd64:3.1",
instance="kubernetes-hostname",
job="kubernetes-nodes-cadvisor",
kubernetes_io_hostname="kubernetes-hostname",
name="k8s_POD_calico-node-xxxxx_kube-system_1c2a925f-c609-11e8-9756-fa163eae1e89_0",
namespace="kube-system",
pod_name="calico-node-xxxxx"
} 0.019708013
container_cpu_usage_seconds_total{
beta_kubernetes_io_arch="amd64",
beta_kubernetes_io_fluentd_ds_ready="true",
beta_kubernetes_io_os="linux",
container_name="calico-node",
cpu="total",
id="/system.slice/docker-b12ea25db1b81117c8f21791b94c627f10bb1fed8625fe6c6c94b29b26325c31.scope",
image="quay.io/calico/node@sha256:563e45196382727b7e3d97640fa88955c75e7210f3bf1870140fa717f9b73b92",
instance="kubernetes-hostname",
job="kubernetes-nodes-cadvisor",
kubernetes_io_hostname="kubernetes-hostname",
name="k8s_calico-node_calico-node-xxxxx_kube-system_1c2a936e-c609-11e8-9756-fa163eae1e89_0",
namespace="kube-system",
pod_name="calico-node-xxxxx"
} 3317.174431967
container_cpu_usage_seconds_total{
beta_kubernetes_io_arch="amd64",
beta_kubernetes_io_fluentd_ds_ready="true",
beta_kubernetes_io_os="linux",
container_name="install-cni",
cpu="total",
id="/system.slice/docker-c98388e79128f17b1c2544531df9b92e72b682015ab4ad896620a756ca345c0c.scope",
image="quay.io/calico/cni@sha256:df90cb1d18182fe41aef0eea293c0045473749e64b8dfd3e420db1a39e5edb39",
instance="kubernetes-hostname",
job="kubernetes-nodes-cadvisor",
kubernetes_io_hostname="kubernetes-hostname",
name="k8s_install-cni_calico-node-xxxxx_kube-system_1c2a936e-c609-11e8-9756-fa163eae1e89_0",
namespace="kube-system",
pod_name="calico-node-xxxxx"
} 54.916640243
그래서 일반적으로 pod이라고 할 수 있는 단위는 namespace와 pod_name으로 지정된 단위라고 볼 수 있습니다. 이런 metric들은 일반적으로 아래와 같이 sum하면 하나의 pod의 metric으로 간주 할 수 있습니다. 아래와 같이 label matching을 제거하면 모든 namespace와 pod에 대해서 수집하게 됩니다.
sum(
rate(container_cpu_usage_seconds_total[1m])
) by (namespace, pod_name, kubernetes_io_hostname)
위의 결과는 아래와 같이 합쳐지고 이 값을 이후 pod의 metric으로 사용하게 됩니다.
{
kubernetes_io_hostname="kubernetes_hostname",
namespace="kube-system",
pod_name="calico-node-xxxxx"
} 0.009238304374996708
...
kubernetes 안에서 pod이 어떻게 object들로 관리 되고 있는가
kubernetes안에서 pod은 그냥 생성 할 수도 있지만 대부분은 owner를 갖게 됩니다. 예외인 경우는 첫번째로는 staticpod 입니다. staticpod은 kubelet과 같은 특수한 agent를 통해 lifecycle이 관리 되고 있기에 owner가 필요없습니다. 두번째로는 그냥 pod 입니다. 이 pod은 owner가 없어서 관리되지 않기에 삭제시 재생성되지 않고 바로 삭제됩니다. 이런 경우 빼고 대부분 확인해 보면 모든 pod들은 owner들을 가지고 있고 이 owner들로 우리는 aggregation 가능 합니다.
예를 들면 아래와 같이 metadata.ownerReferences 를 참고하시면 이게 해당 pod이 어떤 object(daemonset, statefulset, deployment)에 속해 있는지 알 수 있습니다. 예를 들면 이걸 기준으로 아래와 같이 calico-node 라는 daemonset은 아래의 pod을 가지고(관리하고) 있다고 알 수 있고 우리는 이런 기준으로 aggregation 가능함을 알게 됩니다.
apiVersion: v1
kind: Pod
metadata:
ownerReferences:
- apiVersion: apps/v1
blockOwnerDeletion: true
controller: true
kind: DaemonSet
name: calico-node
...
spec:
containers:
...
즉, 이런 ownerReferences를 갖는 pod들은 모두 해당 daemonset에 포함됨으로 이런 ownerReferences를 갖는 pod들을 aggregation하게 되면 그것이 이 daemonset의 데이터가 됨을 알 수 있습니다.
prometheus 데이터로 pod을 aggregation 하는 방법
앞서 말한것 처럼 pod의 aggregation을 하기 위해서는 ownerreference를 수집해야합니다. 이를 위해 kube-state-metric 프로젝트를 사용하면 됩니다. 일반적으로 helm을 이용해 prometheus를 설치했다면 기본으로 설정되어 있습니다. kube-state-metric을 이용하면 deployment들의 개수 상태등과 같은 kubernetes object에 대한 통계를 수집할수 있습니다. 하지만 이보다 이 글에서 더 중요하게 생각하는 부분은 다음과 같습니다.
kube-state-metric은 pod들을 aggregation 하기 위한 metadata들을 제공
일반적으로 prometheus에 수집되는 metric 들은 counter, gauge, histogram과 일반적으로 그 값(value)이 특정한 의미를 갖는 경우들입니다. 하지만 여기서 말하는 이런 metadata들은 value는 전부 1입니다. 왜냐하면 이 metadata들은 해당 vector 안에 label들의 연관관계를 보이기 위함이 주 목적이기 때문입니다.
이런 kube-state-metric을 통해 수집되는 metadata들중 우리에게 필요한 값들은 kube_pod_owner, kube_replicaset_owner등과 같습니다. 이런 metric들은 실제로 값을 찍어보면 아래와 같습니다. 모두 그 value가 1임을 알 수 있습니다.
kube_pod_owner{
app="prometheus",
chart="prometheus-7.0.0",
component="kube-state-metrics",
heritage="Tiller",
job="kubernetes-service-endpoints",
kubernetes_name="prometheus-kube-state-metrics",
kubernetes_namespace="kube-system",
namespace="kube-system",
owner_is_controller="true",
owner_kind="DaemonSet",
owner_name="calico-node",
pod="calico-node-xxxxx",
release="prometheus"
} 1
위에서 말했지만 다시 한번 강조하면 여기서 결국 중요한 label은 namespace, owner_name, pod, owner_kind와 같은 데이터 입니다. 이 값들을 알면 pod의 데이터를 이 값을 기준으로 aggregation 시킬 수 있기 때문입니다. 즉 위의 값은 pod="calico-node-xxxxx" 와 같은 pod은 owner_name="calico-node" 와 같은 daemonset으로 aggregation 가능하다는 것을 알 수 있습니다.
그리고 이런 값들은 아래와 같이 value는 중요하지 않기때문에 필요한 label들만 아래와 같이 max 같은 함수로 추려낼 수 있습니다.
max(
kube_pod_owner
) by (owner_name, owner_kind, pod, namespace)
위와 같이 수행하면 아래와 같이 owner_name와 pod의 관계들이 나오게 됩니다.
{
namespace="kube-system",
owner_kind="DaemonSet",
owner_name="calico-node",
pod="calico-node-xxxxx"
} 1
{
namespace="kube-system",
owner_kind="DaemonSet",
owner_name="csi-rbdplugin",
pod="csi-rbdplugin-xxxxx"
} 1
{
namespace="kube-system",
owner_kind="ReplicaSet",
owner_name="calicoctl-5cb5cc8c56",
pod="calicoctl-5cb5cc8c56-xxxxx"
} 1
...
그렇다면 이제 위와 같은 metadata에 aggregation될 metric 들을 살펴보겠습니다. 위에서 한번 언급한 pod단위로 수집된 container의 metric은 아래와 같습니다.
sum(
rate(container_cpu_usage_seconds_total[1m])
) by (namespace, pod_name, kubernetes_io_hostname)
다시한번 이값을 살펴보면 아래와 같이 kubernetes_io_hostname, namespace, pod_name 으로 정리됩니다.
{
kubernetes_io_hostname="kubernetes_hostname",
namespace="kube-system",
pod_name="calico-node-xxxxx"
} 0.00312516730000425
...
이 값은 위에서 수집된 kube_pod_owner의 label과 차이가 있음을 알 수 있습니다. kube_pod_owner에서 pod은 pod인데 여기에서는 pod_name 이기 때문입니다. 그래서 이 값을 aggregation(vector matching) 하기 위해서는 한쪽 metric의 label에 동일한 label을 만들어야 합니다. 그러기 위해서 prometheus의 label_replace를 사용합니다. 이 function을 이용하면 prometheus vector들의 label을 재설정 가능합니다.
그래서 이를 위해 container_cpu_usage_seconds_total의 label 중 pod_name label을 pod으로 복사합니다. 이러면 kube_pod_owner의 pod label과 vector matching 시킬 수 있기 때문입니다.
그래서 아래와 같이 label을 복사합니다.
label_replace(
sum(
rate(container_cpu_usage_seconds_total[1m])
) by (namespace, pod_name, kubernetes_io_hostname)
,"pod", "$1", "pod_name", "(.+)"
)
그러면 아래와 같이 pod label이 추가 됩니다.
{
kubernetes_io_hostname="kubernetes_hostname",
namespace="kube-system",
pod="calico-node-xxxxx",
pod_name="calico-node-xxxxx"
} 0.00312516730000425
...
이렇게 까지 진행하면 이제 아래와 같이 metadata와 metric을 아래와 같이 aggregation 할 수 있습니다.
max(
kube_pod_owner
) by (owner_name, owner_kind, pod, namespace)
*
on(pod, namespace)
group_right(owner_name, owner_kind)
label_replace(
sum(
rate(container_cpu_usage_seconds_total[1m])
) by (namespace, pod_name, kubernetes_io_hostname)
,"pod", "$1", "pod_name", "(.+)"
)
위의 vector matching은 5가지로 쪼개서 이해할 수 있습니다.
# 1
max(
kube_pod_owner
) by (owner_name, owner_kind, pod, namespace)
# 2
*
# 3
on(pod, namespace)
# 4
group_right(owner_name, owner_kind)
# 5
label_replace(
sum(
rate(container_cpu_usage_seconds_total[1m])
) by (namespace, pod_name, kubernetes_io_hostname)
,"pod", "$1", "pod_name", "(.+)"
)
위는 두 벡터(위의 #1과 #5)중에서 on(pod, namespace) 가 동일한 벡터를 *(multiplication) 와 같이 곱하고 이 결과를 #5 벡터값에 group_right(owner_name, owner_kind)를 추가한다는 의미입니다. 자세한건 Many-to-one and one-to-many vector matches 를 참고하시면 됩니다.
이렇게 하면 결과값은 아래와 같이 owner_name 을 기준으로 pod들 metric이 aggregation 되어 출력됩니다.
{
kubernetes_io_hostname="kubernetes_hostname",
namespace="kube-system",
owner_kind="DaemonSet",
owner_name="calico-node",
pod="calico-node-xxxxx",
pod_name="calico-node-xxxxx"
} 0.00312516730000425
{
kubernetes_io_hostname="kubernetes_hostname",
namespace="kube-system",
owner_kind="DaemonSet",
owner_name="calico-node",
pod="calico-node-yyyyy",
pod_name="calico-node-yyyyy"
} 0.00231112232123345
...
이 값은 아래와 같이 AVG 등의 함수를 이용하면 해당 값들을 평균값들도 생성가능하게 됩니다.
avg(
max(
kube_pod_owner
) by (owner_name, owner_kind, pod, namespace)
*
on(pod, namespace)
group_right(owner_name, owner_kind)
label_replace(
sum(
rate(container_cpu_usage_seconds_total[1m])
) by (namespace, pod_name, kubernetes_io_hostname)
,"pod", "$1", "pod_name", "(.+)"
)
) by (namespace, owner_kind, owner_name)
결과는 아래와 같이 모든 replicaset, daemonset, statefulset pod들을 aggregation 하고 평균값을 내줄 수 있습니다.
{
namespace="kube-system",
owner_kind="DaemonSet",
owner_name="calico-node"
} 0.01108754473353368
{
namespace="rook-ceph",
owner_kind="ReplicaSet",
owner_name="rook-ceph-mgr-a-88d56c679"
} 0.0036500768999985665
{
namespace="kube-system",
owner_kind="StatefulSet",
owner_name="csi-rbdplugin-attacher"
} 0.00247490775230173
...
deployment로 aggregation 하기 위한 방법
daemonset과 statefulset은 위와 같은 방법들을 이용하면 쉽게 aggregation 가능 합니다. 다만 deployment와 같은 경우는 replicaset과 같은 ownerreference를 한번 더 거쳐야 합니다. (pod -> replicaset -> deployment) 다시 말해 다른 object와 달리 2단계의 ownerreference 체크가 필요합니다. 이 케이스를 설명하는 것은 이런 방법을 응용하면 이후에도 다양한 형태의 object들을 aggregation 할 수 있다고 생각하기 때문입니다.
다만 이부분 부터는 kube-state-metrics 에 add kube_replicatset_owner metric과 같은 커밋이 있어야 합니다. 왜냐하면 아래에서 나오는 kube_replicaset_owner는 위의 커밋이 있어야 수집되기 때문입니다. 이건 kube-state-metrics 다음버전에 들어갈 것으로 예상되고 아직은 추가 되지 않은 상태입니다. 대충 해당 커밋을 포함해서 이미지를 빌드해서 사용하면 됩니다. 아니면 미리 빌드해둔 leoh0/kube-state-metrics:latest 이미지를 쓰셔도 됩니다.
그렇다면 kube_pod_owner 와 kube_replicaset_owner 를 어떻게 vector matching 하는지 설명 드리겠습니다. 즉, pod -> replicaset -> deployment 연계중 우선 replicaset -> deployment 부터 조합하는 것입니다. 이런 metadata들을 먼저 vector matching하는 것은 아무래도 이런 metadata가 metric 수보다는 적기에 먼저 연산하는 것이 유리하기 때문입니다.
이제 match할 kube_pod_owner는 위에서도 사용것과 같은 아래 값입니다.
max(
kube_pod_owner
) by (owner_name, owner_kind, pod, namespace)
이 결과중 아래와 같이 ReplicaSet 데이터가 있음을 확인 할 수 있습니다.
{
namespace="rook-ceph",
owner_kind="ReplicaSet",
owner_name="rook-ceph-mgr-a-88d56c679",
pod="rook-ceph-mgr-a-88d56c679-7kwgc"
} 1
...
이런 위의 데이터와 연결할 kube_replicaset_owner를 살펴보면 아래와 같이 확인할 수 있습니다.
max(
kube_replicaset_owner
) by (namespace, owner_name, owner_kind, replicaset)
이 데이터는 아래와 같습니다.
{
namespace="rook-ceph",
owner_kind="Deployment",
owner_name="rook-ceph-mgr-a",
replicaset="rook-ceph-mgr-a-88d56c679"
} 1
즉, kube_pod_owner의 owner_name 가 kube_replicaset_owner의 replicaset와 일치 될경우(물론 namespace도 동일) vector가 매칭 될 수 있습니다.
그러면 이제 단순한 생각의 흐름으로 이 두 벡터를 매칭 시키는 방법을 설명드립니다. 쿼리를 최적화 하려면 다른 방법들도 가능하지만 다양한 방법들이 가능하다는 것을 설명드리고자 합니다.
우리가 원하는 결과물은 아래와 같습니다. owner_kind owner_name은 kube_replicaset_owner용 label value를 사용하고 pod은 kube_pod_owner의 label value를 사용하는 것입니다. 이런 metadata를 만들어야 나중에 pod metric을 아래 metadata에 match 시키면 deployment로 수집될 수 있기 때문입니다. 이를 간단히 설명하면 아래와 같습니다.
{
namespace="rook-ceph", // kube_pod_owner, kube_replicaset_owner 동일
owner_kind="Deployment", // kube_replicaset_owner 값
owner_name="rook-ceph-mgr-a", // kube_replicaset_owner 값
pod="rook-ceph-mgr-a-88d56c679-7kwgc" // kube_pod_owner 값
} 1
위와 같이 구성하기 위해 우선 kube_replicaset_owner를 -> kube_pod_owner 로 매칭 시키도록 합니다. 결국 base는 kube_pod_owner 가 되기 때문에 이 owner_kind를 나중에 Deployment로 세팅하기 위한 값을 세팅합니다.
label_replace(
max(
kube_replicaset_owner
) by (namespace, owner_name, owner_kind, replicaset)
,"new_kind", "$1", "owner_kind", "(.+)"
)
이런 결과는 아래와 같이 new_kind="Deployment" 가 생깁니다.
{
namespace="rook-ceph",
new_kind="Deployment",
owner_kind="Deployment",
owner_name="rook-ceph-mgr-a",
replicaset="rook-ceph-mgr-a-88d56c679"
} 1
이제 나중에 owner_name도 나중에 덮어쓰기 위한 값을 세팅합니다. 왜냐하면 kube_pod_owner에 owner_name에 매칭하기 위해서 기존의 replicaset 을 owner_name으로 변경하기 때문에 미리 owner_name을 나중에 다시 사용하기 위해 new_name으로 복사해 두는 겁니다.
label_replace(
label_replace(
max(
kube_replicaset_owner
) by (namespace, owner_name, owner_kind, replicaset)
,"new_kind", "$1", "owner_kind", "(.+)"
)
,"new_name", "$1", "owner_name", "(.+)"
)
new_name="rook-ceph-mgr-a" 와 같이 추가 되어 있는 것을 알 수 있습니다.
{
namespace="rook-ceph",
new_kind="Deployment",
new_name="rook-ceph-mgr-a",
owner_kind="Deployment",
owner_name="rook-ceph-mgr-a",
replicaset="rook-ceph-mgr-a-88d56c679"
} 1
또, 아래와 같이 나중에 match시키기 위해 kube_pod_owner의 owner_name과 match하기 위해 replicaset값을 owner_name로 변경합니다.
label_replace(
label_replace(
label_replace(
max(
kube_replicaset_owner
) by (namespace, owner_name, owner_kind, replicaset)
,"new_kind", "$1", "owner_kind", "(.+)"
)
,"new_name", "$1", "owner_name", "(.+)"
)
,"owner_name", "$1", "replicaset", "(.+)"
)
owner_name이 owner_name="rook-ceph-mgr-a" -> owner_name="rook-ceph-mgr-a-88d56c679" 로 변경됩니다.
{
namespace="rook-ceph",
new_kind="Deployment",
new_name="rook-ceph-mgr-a",
owner_kind="Deployment",
owner_name="rook-ceph-mgr-a-88d56c679",
replicaset="rook-ceph-mgr-a-88d56c679"
} 1
이제 준비한 이 벡터를 kube_pod_owner 에 match합니다.
label_replace(
label_replace(
label_replace(
max(
kube_replicaset_owner
) by (namespace, owner_name, owner_kind, replicaset)
,"new_kind", "$1", "owner_kind", "(.+)"
)
,"new_name", "$1", "owner_name", "(.+)"
)
,"owner_name", "$1", "replicaset", "(.+)"
)
*
on(owner_name, namespace)
group_right(new_name, new_kind)
max(
kube_pod_owner
) by (owner_name, owner_kind, pod, namespace)
결과는 아래와 같이 kube_pod_owner 벡터에 new_name과 new_kind가 추가되서 match됩니다.
{
namespace="rook-ceph",
new_kind="Deployment",
new_name="rook-ceph-mgr-a",
owner_kind="ReplicaSet",
owner_name="rook-ceph-mgr-a-88d56c679",
pod="rook-ceph-mgr-a-88d56c679-7kwgc"
} 1
여기에서 우리는 new_kind를 우리가 원하는 owner_kind에 덮어씁니다.
label_replace(
label_replace(
label_replace(
label_replace(
max(
kube_replicaset_owner
) by (namespace, owner_name, owner_kind, replicaset)
,"new_kind", "$1", "owner_kind", "(.+)"
)
,"new_name", "$1", "owner_name", "(.+)"
)
,"owner_name", "$1", "replicaset", "(.+)"
)
*
on(owner_name, namespace)
group_right(new_name, new_kind)
max(
kube_pod_owner
) by (owner_name, owner_kind, pod, namespace)
,"owner_kind", "$1", "new_kind", "(.+)"
)
아래와 같이 owner_kind="ReplicaSet" -> owner_kind="Deployment" 로 변경 됩니다.
{
namespace="rook-ceph",
new_kind="Deployment",
new_name="rook-ceph-mgr-a",
owner_kind="Deployment",
owner_name="rook-ceph-mgr-a-88d56c679",
pod="rook-ceph-mgr-a-88d56c679-7kwgc"
} 1
또 비슷하게 new_name으로 owner_name을 덮어씁니다.
label_replace(
label_replace(
label_replace(
label_replace(
label_replace(
max(
kube_replicaset_owner
) by (namespace, owner_name, owner_kind, replicaset)
,"new_kind", "$1", "owner_kind", "(.+)"
)
,"new_name", "$1", "owner_name", "(.+)"
)
,"owner_name", "$1", "replicaset", "(.+)"
)
*
on(owner_name, namespace)
group_right(new_name, new_kind)
max(
kube_pod_owner
) by (owner_name, owner_kind, pod, namespace)
,"owner_kind", "$1", "new_kind", "(.+)"
)
,"owner_name", "$1", "new_name", "(.+)"
)
아래와 같이 owner_name="rook-ceph-mgr-a-88d56c679" -> owner_name="rook-ceph-mgr-a" 로 변경 됩니다.
{
namespace="rook-ceph",
new_kind="Deployment",
new_name="rook-ceph-mgr-a",
owner_kind="Deployment",
owner_name="rook-ceph-mgr-a",
pod="rook-ceph-mgr-a-88d56c679-7kwgc"
} 1
여기에서 사용할 owner_name, owner_kind, pod, namespace 만 추려냅니다.
max(
label_replace(
label_replace(
label_replace(
label_replace(
label_replace(
max(
kube_replicaset_owner
) by (namespace, owner_name, owner_kind, replicaset)
,"new_kind", "$1", "owner_kind", "(.+)"
)
,"new_name", "$1", "owner_name", "(.+)"
)
,"owner_name", "$1", "replicaset", "(.+)"
)
*
on(owner_name, namespace)
group_right(new_name, new_kind)
max(
kube_pod_owner
) by (owner_name, owner_kind, pod, namespace)
,"owner_kind", "$1", "new_kind", "(.+)"
)
,"owner_name", "$1", "new_name", "(.+)"
)
) by (owner_name, owner_kind, pod, namespace)
아래와 같이 벡터가 추려진것을 확인 할 수 있습니다.
{
namespace="rook-ceph",
owner_kind="Deployment",
owner_name="rook-ceph-mgr-a",
pod="rook-ceph-mgr-a-88d56c679-7kwgc"
} 1
grafana 에 kubernetes aggregation dashboard 만들기
우선 예제로 설명할 dashboard는 아래와 같습니다.
download kubernetes aggregation grafana dashboard
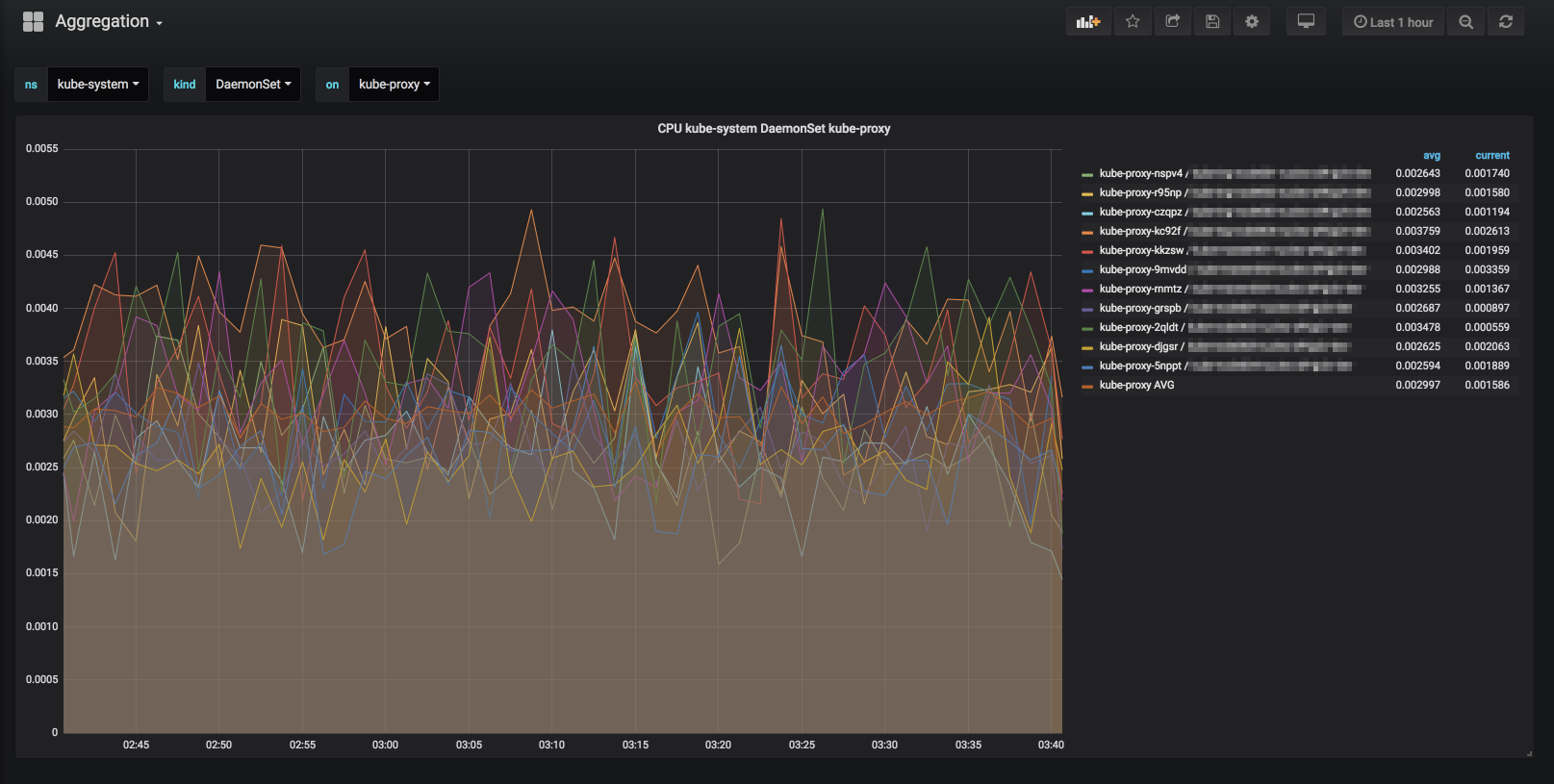
Kubernetes Aggregation Metrics
우선 해당 dashboard를 사용하려면 grafana/grafana:5.3.0-beta3 와 같은 grafana 5.3.0 이상을 사용해야 합니다. 왜냐하면 prometheus의 $__interval과 같은 range query 옵션을 넣었기 때문입니다. 만약 이전버전 grafana를 그대로 이용하실 분들은 그냥 $__interval과 같은 부분을 1m 과 같이 변경하면 사용 가능합니다. 하지만 이 query를 사용해야 보다 기간에 따른 적당한 양의 data를 가져올 수 있어 더욱 용이 합니다.
이 dashboard에서 사용한 metadata aggregation을 위해 아래와 같은 query문을 만들었습니다. 이 쿼리의 결과는 모든 pod, namespace들의 owner_name와 owner_kind들을 출력해줍니다.
max(
max(
kube_replicaset_owner
) by (namespace, owner_name, owner_kind, replicaset)
*
on(replicaset, namespace)
group_right(owner_name, owner_kind)
label_replace(
max(
kube_pod_owner{namespace="$ns",owner_kind="ReplicaSet"}
) by (owner_name, pod, namespace)
, "replicaset", "$1", "owner_name", "(.+)"
)
or
kube_pod_owner
) by (owner_name, owner_kind, pod, namespace)
이 쿼리는 아래와 같이 분리해서 해석할 수 있습니다. 우선 아래는 사실 위 챕터에서 replicaset -> deployment match를 조금 더 튜닝한 버전입니다.
max(
kube_replicaset_owner
) by (namespace, owner_name, owner_kind, replicaset)
*
on(replicaset, namespace)
group_right(owner_name, owner_kind)
label_replace(
max(
kube_pod_owner{namespace="$ns",owner_kind="ReplicaSet"}
) by (owner_name, pod, namespace)
, "replicaset", "$1", "owner_name", "(.+)"
)
여기에 아래와같이 기존의 모든 pod들의 owner 관련 정보를 추가합니다.
or
kube_pod_owner
dashboard에 대해서 간략히 설명하면 우선 다음과 같습니다.
ns variables은 namespace를 의미하며 아래와 같은 결과에서 "^{namespace=\"(.+?)\",.*$" 와 같은 regrex로 결과를 추출한 값입니다.
max(
max(
kube_replicaset_owner
) by (namespace, owner_name, owner_kind, replicaset)
*
on(replicaset, namespace)
group_right(owner_name, owner_kind)
label_replace(
max(
kube_pod_owner{namespace="$ns",owner_kind="ReplicaSet"}
) by (owner_name, pod, namespace)
, "replicaset", "$1", "owner_name", "(.+)"
)
or
kube_pod_owner
) by (owner_name, owner_kind, pod, namespace)
kind variables는 여기에 {namespace="$ns"} 가 정의된 상태에서 검색 되도록 하고 "^.*owner_kind=\"(.+?)\",.*$" 와 같이 추출합니다.
max(
max(
kube_replicaset_owner{namespace="$ns"}
) by (namespace, owner_name, owner_kind, replicaset)
*
on(replicaset, namespace)
group_right(owner_name, owner_kind)
label_replace(
max(
kube_pod_owner{namespace="$ns",owner_kind="ReplicaSet"}
) by (owner_name, pod, namespace)
, "replicaset", "$1", "owner_name", "(.+)"
)
or
kube_pod_owner{namespace="$ns"}
) by (owner_name, owner_kind, pod, namespace)
on variables는 여기에 {namespace="$ns",owner_kind="$kind"} 가 정의된 상태에서 검색되고 "^.*owner_name=\"(.+?)\",.*$" 로 추출 되도록 합니다.
max(
max(
kube_replicaset_owner{namespace="$ns",owner_kind="$kind"}
) by (namespace, owner_name, owner_kind, replicaset)
*
on(replicaset, namespace)
group_right(owner_name, owner_kind)
label_replace(
max(
kube_pod_owner{namespace="$ns",owner_kind="ReplicaSet"}
) by (owner_name, pod, namespace)
, "replicaset", "$1", "owner_name", "(.+)"
)
or
kube_pod_owner{namespace="$ns",owner_kind="$kind"}
) by (owner_name, owner_kind, pod, namespace)
실제 metric은 아래와 같습니다. 위의 쿼리에 보통 metric을 join 시키는 방식입니다. 각각 pod 각각의 상태와 avg 한 그래프를 배치시키는 방식입니다.
query A
max(
max(
kube_replicaset_owner{namespace="$ns",owner_kind="$kind",owner_name="$on"}
) by (namespace, owner_name, owner_kind, replicaset)
*
on(replicaset, namespace)
group_right(owner_name, owner_kind)
label_replace(
max(
kube_pod_owner{namespace="$ns",owner_kind="ReplicaSet"}
) by (owner_name, pod, namespace)
, "replicaset", "$1", "owner_name", "(.+)"
)
or
kube_pod_owner{namespace="$ns",owner_kind="$kind",owner_name="$on"}
) by (owner_name, owner_kind, pod, namespace)
*
on(pod, namespace)
group_right(owner_kind, owner_name)
label_replace(
sum by(pod_name, namespace, kubernetes_io_hostname) (
rate(container_cpu_usage_seconds_total{namespace="$ns"}[$__interval])
), "pod", "$1", "pod_name", "(.+)"
)
query B
avg(
max(
max(
kube_replicaset_owner{namespace="$ns",owner_kind="$kind",owner_name="$on"}
) by (namespace, owner_name, owner_kind, replicaset)
*
on(replicaset, namespace)
group_right(owner_name, owner_kind)
label_replace(
max(
kube_pod_owner{namespace="$ns",owner_kind="ReplicaSet"}
) by (owner_name, pod, namespace)
, "replicaset", "$1", "owner_name", "(.+)"
)
or
kube_pod_owner{namespace="$ns",owner_kind="$kind",owner_name="$on"}
) by (owner_name, owner_kind, pod, namespace)
*
on(pod, namespace)
group_right(owner_kind, owner_name)
label_replace(
sum by(pod_name, namespace, kubernetes_io_hostname) (
rate(container_cpu_usage_seconds_total{namespace="$ns"}[$__interval])
), "pod", "$1", "pod_name", "(.+)"
)
) by (owner_name, owner_kind, namespace)
실제 여기 있는 metric graph나 variable 같은 경우 최적화를 하지 않은 쿼리문이라서 속도가 느립니다. 이런식으로 많은 join(vector matching)을 하면 쿼리 성능에도 영향을 크게 미칩니다. 이건 그냥 복잡한 케이스 해결의 예시로 참고하시면 좋을 것 같습니다. 실제로 예를 들어 namespace나 kind를 variable로 정리하는 것은 더 간단한 쿼리를 사용합니다.
결론
사실 여기까지 설명한것은 이런 기법들중 굉장히 일부분을 설명한 것입니다. 사실 prometheus를 kubernetes에 제대로 연동하기 위해서는 추가적인 metadata들을 더 수집하고 custom metric들을 위한 labeling 작업 등등 많은 부분들이 남아 있습니다. 다만 이런 방법들을 적용하면 기존에 만들지 못한 패턴들을 탐지할 수 있는 그래프들을 만들 단초가 될것으로 기대됩니다.