
linuxkit with kubernetes
… As a developer and sometimes system administrator, one of the scariest things I ever encounter is a server that’s been running for ages which has seen multiple upgrades of system and application software. … Need to upgrade? No problem. Build a new, upgraded system and throw the old one away. New app revision? Same thing. Build a server (or image) with a new revision and throw away the old ones. …
2013년 해당 글을 읽었을때만 해도 과연 언제 이런게 가능할까 고민 했었던 기억이 난다. cloud를 위한 linux custom 배포판 등은 crowbar과 같은 프로젝트들에서 진행이 되고 있었으나 container가 아닌 이상은 이런 하이퍼바이저들을 지속적으로 교체하기엔 큰 부담이 있었다.
컨테이너 기술이 발전하며 이런 immutable한 이미지를 만들기 위한 여러가지 방법론들이 있었으나 개인적인 취향이나 상황에 맞게 쓸만하지 못했으나 최근 시간이 남아서 새롭게 조사하다 linuxkit이 많은 안정화를 가져온것을 확인해서 삽질을 시작했다.
linuxkit
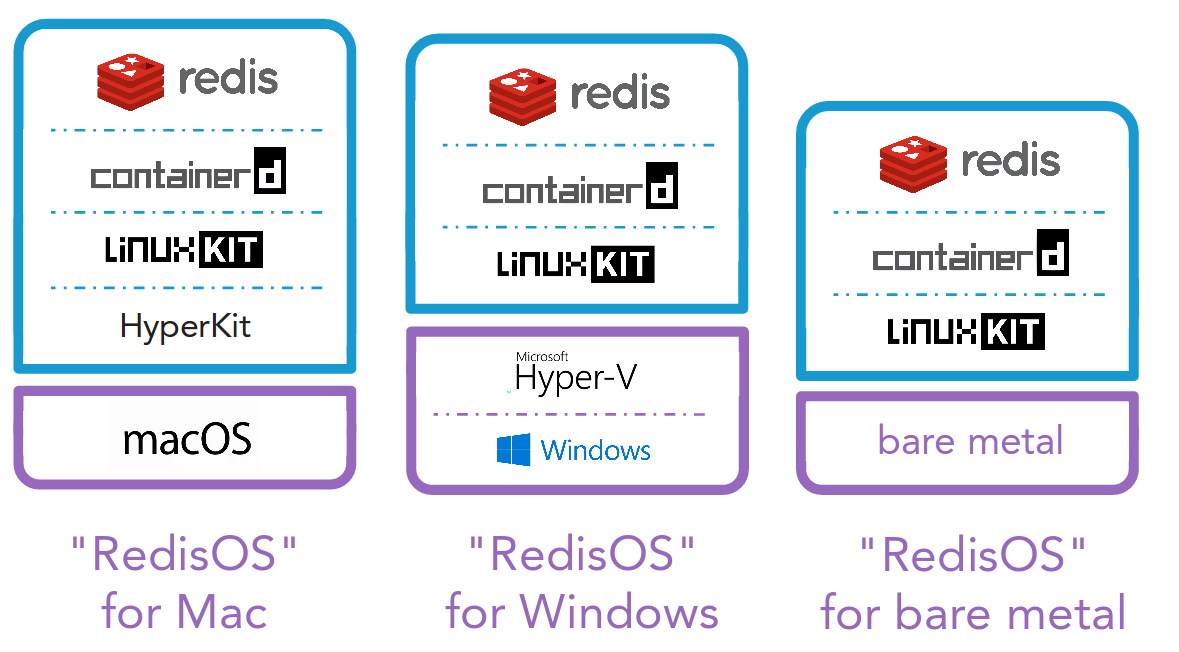
linuxkit 은 아주 간단히 말해서 컨테이너를 위한 커스텀 리눅스 배포판을 만들고, 배포하고, 실행하기 위한 툴이다.
단도직입적으로 linuxkit을 선호해서 사용하고 하는 이유는 다음과 같다.
- 블럭을 쌓는것처럼 kernel 부터 모두
docker image이다. - 한가지
yaml작성으로 로컬 하이퍼바이저(qemu, xhyve, …), 클라우드(gcp, aws, …), 베어마탈을 위한 Pxe들을 지원 가능하다. immutable한 이미지 이다.- 내가 설정한 것외에는
아무것도 존재 하지 않아서보안적으로 뛰어나다.
물론 이런 장점은 이런 단점으로 볼 수도 있다.
- 블럭을 쌓는거에따라 조합이 L * M * N 과 같이 늘어나면서 안되는 경우의 수가 많아 테스트가 중요해진다.
- 한가지 yaml으로 모든걸 지원하기 위해 지원하는 플랫폼에 대한 코드의 준비나 테스트가 필요하다.
- immutable 하다고 해도 외부 요인이 있는한 (eg. 컨테이너 이미지 다운로드) 문제가 생길 가능성은 충분히 남아 있다.
- 이미지가 배포된뒤에 디버깅 할 수 있는 수단이 아주 제한적이다.
간단한 예제들이 많이 있으니 직접 돌려보면 이해가 쉬울 것 같다.
kubernetes를 좀 더 쉽게 관리하려면

kubernetes
From Using Minikube to Create a Cluster
kubernetes를 관리한다고 생각하면 수많은 오퍼레이션을 생각하게 되지만 만약 배포를 간단하게 만든다면(eg. golden image, linuxkit 등) 생각보다 많은 어려운 작업들을 심플하게 만들 수 있다. 예를 들면 다음과 같다.
전통적인 kubernetes upgrade 방법
예를 들어서 kubernetes upgrade는 크게 2가지로 이루어져 있다.
control plane(apiserver, controller manager, scheduler)upgradekubeadm같은 툴을 사용하지 않고 master HA해서 사용하게 된다면 결국 master노드 하나씩 drain 이후 static pod들의 manifest를 수정해서 업그레이드 한후 다시 투입(uncordon) 시킨다.
node agent(kubelet)upgrade- drain 이후 kubelet version upgrade 이후 다시 노드를 투입(uncordon)해야 한다.
위와 같은 작업을 하게되면 새로추가되는 노드는 필요없지만 migration 비용이 크고, 작업이 길어지고, 롤백이 힘들어지고, 과거로부터 지속된 업그레이드로 인한 문제(A->B->C 로 업그레이드 한것과 B->C 만 업그레이드한것이 다른 경우) 등에서 자유롭지 못하다.
노드 추가를 통한 kubernetes upgrade 방법
-
control plane(apiserver, controller manager, scheduler)upgrade- control plane은 새로운 static pod이 있는 master node를 추가한 뒤 과거 버전의 master node를 제거(drain) 하는 식으로 업그레이드가 가능하다.
-
node agent(kubelet)upgrade- node agent도 비슷하게 새로운 버전의 노드들을 가능한 만큼 추가 하고 이전 버전 노드들을
cordon시킨 상태에서 낮은 버전의 노드들을 제거(drain) 혹은 새로운 버전 노드로 재설치해서 사용하는식으로 업그레이드 가능하다.
- node agent도 비슷하게 새로운 버전의 노드들을 가능한 만큼 추가 하고 이전 버전 노드들을
여기서도 결국 master와 node의 2종류의 이미지를 관리해야 한다. 물론 모두 master 이미지로 만들고 node로 사용가능하나 깔끔하진 못한 방법이다. 이런걸 해결 하기 위해서는 결국 self hosted kubernetes 를 고려해야 한다.
self hosted kubernetes 를 이용하게 되면 master node의 라벨을 같는 node가 master의 역할을 수행할뿐(apiserver, controller manager, scheduler를 갖는 node) 모두 동일한 node로 구성 가능하다. self hosted kubernetes는 아직 alpha state이나 나중에 이게 default가 되기때문에 미리 봐도 좋을것 같다. 이걸 적용하면 upgrade 절차는 더욱 단순해 진다.
-
control plane(apiserver, controller manager, scheduler)upgrade- control plane은 apiserver는 daemonset, controller manager, scheduler는 deployment가 되기 때문에 image 교체정도로 업그레이드가 끝나게 된다.
kubectl set image ds/kube-apiserver \ kube-apiserver=gcr.io/google_containers/kube-apiserver-amd64:v1.10.0 kubectl set image deploy/kube-scheduler \ kube-scheduler=gcr.io/google_containers/kube-scheduler-amd64:v1.10.0 kubectl set image deploy/kube-controller-manager \ kube-controller-manager=gcr.io/google_containers/kube-controller-manager-amd64:v1.10.0 -
node agent(kubelet)upgrade- 일반과 동일
즉, self hosted kubernetes를 적용하면 master와 node 이미지를 별개로 이미지를 준비하고, 작업을 따로 준비 하지 않아도 된다. 결국 node image만 준비하면 되고 이건 kubelet agent들이 있는 이미지만 준비하면 된다는 것이다.
에스칼레이터 발판 같은 kubernetes 노드 관리
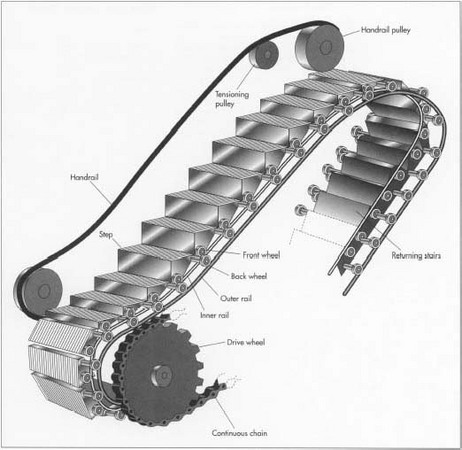
escalator
From Escalator Background
앞서 설명한 글을 보다 자세히 설명하기 위해서 에스칼레이터의 그림을 가져왔다. 에스칼레이터의 발판은 무한으로 생성되는 것이 아닌 사용된 발판이 사용되고 다시 한바퀴 돌아 재사용되는 식으로 사람을 옮기게 된다.
앞에서 kubernetes upgrade를 통해서 설명하려고 한것도 이와 비슷하게 kubernetes node도 이런 life cycle을 갖게한다고 보면 된다.
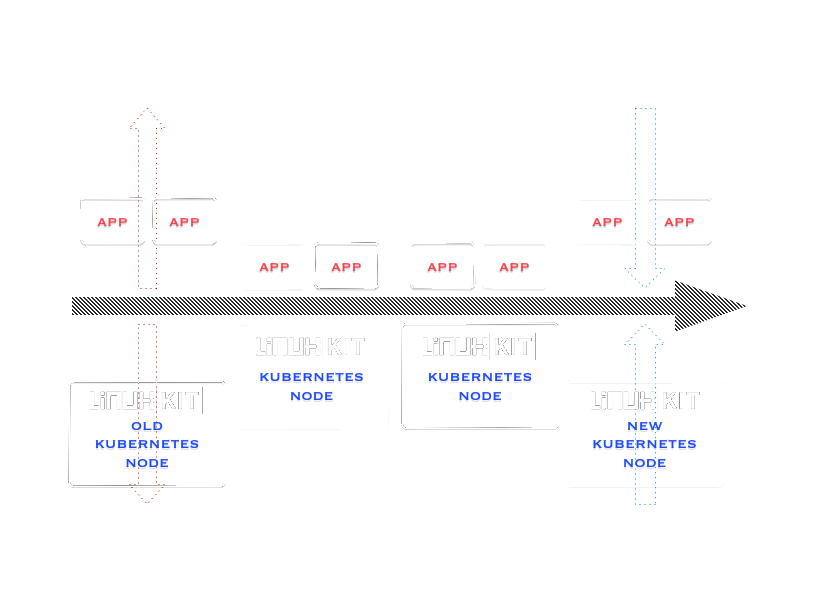
swapable nodes
즉, 에스칼레이터나 캐터필러와 같이 계속 업그레이드, docker version 업데이트등과 같은 작업이나 확장등은 신규 노드를 추가하고 옛날 노드를 삭제한다. 그래서 여기에 사용되는 노드들을 빠르게 추가하고 안전하게 관리하기 위해서 linuxkit과 같은 immutable한 이미지 사용을 고려했다.
linuxkit + kubernetes
그렇다면 linuxkit으로 kubernetes를 배포하려면 어떤걸 고려하고 어떻게 해야되나를 생각해보면 다음과 같다.
우선 linuxkit으로 돌리려면 minikube와 같은 allinone 솔루션이 아니라 (거의)무조건 멀티노드를 전제하게 된다. 이를 위해서 기본적으로 cni를 통한 weave를 지원하도 있다. 하지만 다양한 network등을 적용해 볼 수 있다. 나 같은 경우엔 calico와 cilium등을 이용해서 배포하는 것들을 테스트 했다.
그렇다면 어디에 배포할 수 있는 가는 내가 테스트 해본것은 우선 mac(xhyve), qemu(ubuntu), gcp, aws 에서 였다. 앞서 말한것 처럼 사실 각각에서 되고 안되고가 있기때문에 각각에 대한 주의사항이나 사용경험등을 공유한다. 우선 전체적으로 4.9.78 정도의 커널을 사용하는게 현재까지 가장 stable 하고 성공확률이 높다.
물론 이것을 보더라도 만약 이런 정보들이 처음이면 삽질하는데 엄청난 시간이 들어갈 수 밖에 없다. 왜냐하면 우선 debug할 수 있는 수단이 제한적이고 모든 것이 컨테이너이기 때문에 각각이 네임스페이스에 갇혀있고 디스크의 마운트 구조를 이해하지 못하면 어떤 파일들이 어디에 있는지 조차도 파악하기가 힘들다. 하지만 모든건 시간이 해결 해 줄 것이다.
사용 가능한 platform들
mac(xhyve)
만약 mac이 있다면 우선 제일 쉽게 시작할 수 있다. brew나 go를 통해서 binary(linuxkit)을 쉽게 얻을 수 있고 설치 생성시 바로 성공을 경험 할 수 있다. README 대로 따라하면 된다.
하지만 거기 까지다.
그 이상을 할 수가 없다는 것을 알게 된다. 만약 본인이 L2 네트워크나 L3 네트워크를 컨트롤 하고 싶어져도, hyperkit과 vpnkit을 조작할 수 없고 심지어 dhcp 도 컨트롤 할 수 없다는 사실이 답답하게 느껴질 것이다. 그리고 또한 호스트의 16G 정도의 메모리로는 4G instance를 2-3개 정도 밖에 못쓴다. 4G 메모리가 필요한 이유는 cilium를 사용할 때이며 이때 eBPF map을 관리하는데 4G 정도가 들어가기 때문이다. 물론, calico나 weave를 쓰면 더 많은 노드를 띄울 수 있다.
qemu(ubuntu)
사실 메모리가 많은 하이퍼바이저만 구할 여유가 된다면 이 방법이 가장 좋을 수도 있다. 물론 하지만 본인이 linux의 internel network을 조작하는데 익숙 하지 않다면 간단하지 않을 수 있다. README에 설명되어 있으나 저정도로는 간단하지 않다. 특히 qemu로 띄웠을때는 서로 vm들끼리 공유되지 않는 네트워크 상태이지 않기때문에 아래같은 스크립트로 internel network을 생성해서 사용해야 한다.
그래서 아래의 스크립트를 참고해서 네트워크를 만든다. 아래 스크립트를 설명하면 다음과 같은 일 들을 한다.
docker,qemu,golang설치- vm이 사용할 bridge 생성 및 이에 대한 dhcp 설정
- 해당 bridge의 vm이 nat로 인터넷 연결 할 수 있도록 설정
- linuxkit 설치 및 접속할 sshkey 생성
#!/bin/sh
if [ "$(id -u)" != "0" ]; then
echo "This script must be run as root" 1>&2
exit 1
fi
set -ex
apt update
apt install -y apt-transport-https ca-certificates curl software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | apt-key add -
apt-key fingerprint 0EBFCD88
#add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu \
# $(lsb_release -cs) \
# stable"
# 18.04는 repo가 아직 없어서 artful을 이용해야 한다.
add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu \
artful \
stable"
apt update
apt install -y docker-ce uml-utilities qemu-kvm bridge-utils virtinst libvirt-bin golang-go
virsh net-destroy default
virsh net-autostart --disable default
ip link add virbr10-dummy address $(hexdump -vn3 -e '/3 "52:54:00"' -e '/1 ":%02x"' -e '"\n"' /dev/urandom) type dummy
brctl addbr virbr10
brctl stp virbr10 on
brctl addif virbr10 virbr10-dummy
ip address add 10.0.0.1/8 dev virbr10 broadcast 192.168.100.255
echo "net.ipv4.ip_forward=1" >> /etc/sysctl.conf
echo "net.ipv4.conf.all.forwarding=1" >> /etc/sysctl.conf
sysctl -p
iptables -t nat -A POSTROUTING -s 10.0.0.0/8 -d 224.0.0.0/24 -j RETURN
iptables -t nat -A POSTROUTING -s 10.0.0.0/8 -d 255.255.255.255/32 -j RETURN
iptables -t nat -A POSTROUTING -s 10.0.0.0/8 ! -d 10.0.0.0/8 -p tcp -j MASQUERADE --to-ports 1024-65535
iptables -t nat -A POSTROUTING -s 10.0.0.0/8 ! -d 10.0.0.0/8 -p udp -j MASQUERADE --to-ports 1024-65535
iptables -t nat -A POSTROUTING -s 10.0.0.0/8 ! -d 10.0.0.0/8 -j MASQUERADE
iptables -t filter -A FORWARD -d 10.0.0.0/8 -o virbr10 -m conntrack --ctstate RELATED,ESTABLISHED -j ACCEPT
# 밖으로(169.254.0.0/16)으로 메타가 새면 하이퍼바이저의 메타를 들고온다..
iptables -t filter -A FORWARD -s 10.0.0.0/8 ! -d 169.254.0.0/16 -i virbr10 -j ACCEPT
iptables -t filter -A FORWARD -s 10.0.0.0/8 -d 169.254.0.0/16 -i virbr10 -j DROP
ip l set virbr10-dummy up
ip l set virbr10 up
mkdir -p /etc/qemu/
echo 'allow virbr10' > /etc/qemu/bridge.conf
mkdir -p /var/lib/dnsmasq/virbr10
touch /var/lib/dnsmasq/virbr10/hostsfile
touch /var/lib/dnsmasq/virbr10/leases
cat > /var/lib/dnsmasq/virbr10/dnsmasq.conf << EOF
# Only bind to the virtual bridge. This avoids conflicts with other running
# dnsmasq instances.
except-interface=lo
interface=virbr10
bind-dynamic
# If using dnsmasq 2.62 or older, remove "bind-dynamic" and "interface" lines
# and uncomment these lines instead:
#bind-interfaces
listen-address=10.0.0.1
# IPv4 addresses to offer to VMs. This should match the chosen subnet.
dhcp-range=10.0.0.2,10.15.255.254
# 굳이 안해도 되나 아이피 일괄적으로 주려면 이런게 제일 편하다.
dhcp-host=8a:a0:33:57:08:0a,10.0.0.2
dhcp-host=8a:a0:33:57:08:0b,10.0.0.3
dhcp-host=8a:a0:33:57:08:0c,10.0.0.4
dhcp-host=8a:a0:33:57:08:0d,10.0.0.5
dhcp-host=8a:a0:33:57:08:0e,10.0.0.6
# Set this to at least the total number of addresses in DHCP-enabled subnets.
dhcp-lease-max=1000
# File to write DHCP lease information to.
dhcp-leasefile=/var/lib/dnsmasq/virbr10/leases
# File to read DHCP host information from.
dhcp-hostsfile=/var/lib/dnsmasq/virbr10/hostsfile
# Avoid problems with old or broken clients.
dhcp-no-override
# https://www.redhat.com/archives/libvir-list/2010-March/msg00038.html
strict-order
EOF
cat > /etc/systemd/system/dnsmasq@.service << EOF
# '%i' becomes 'virbr10' when running `systemctl start dnsmasq@virbr10.service`
# Remember to run `systemctl daemon-reload` after creating or editing this file.
[Unit]
Description=DHCP and DNS caching server for %i.
After=network.target
[Service]
ExecStart=/usr/sbin/dnsmasq -k --conf-file=/var/lib/dnsmasq/%i/dnsmasq.conf
ExecReload=/bin/kill -HUP $MAINPID
Restart=on-failure
RestartSec=5
[Install]
WantedBy=multi-user.target
EOF
systemctl start dnsmasq@virbr10.service
echo '''Host *
StrictHostKeyChecking no
UserKnownHostsFile /dev/null
User root''' > /root/.ssh/config
export PATH=~/go/bin:$PATH
export PATH=/usr/libexec:$PATH
echo '''export PATH=~/go/bin:$PATH
export PATH=/usr/libexec:$PATH''' >> ~/.bashrc
git clone https://github.com/leoh0/kubernetes
go get -u github.com/linuxkit/linuxkit/src/cmd/linuxkit
echo -e "\n\n\n" | ssh-keygen -t rsa -N ""
echo '''
# cd /root/kubernetes
make all
KUBE_CLEAR_STATE=true KUBE_MAC=8a:a0:33:57:08:0a KUBE_NETWORKING="bridge,virbr10" ./boot.sh
KUBE_CLEAR_STATE=true KUBE_MAC=8a:a0:33:57:08:0b KUBE_NETWORKING="bridge,virbr10" ./boot.sh 1 \
10.0.0.2:6443 --token 3wkfov.fj3ywmkva55nr4p7 --discovery-token-ca-cert-hash \
sha256:ee14b16af5775cfa65215cff0f6fe2807d35b23a4a3dd8a72507e93292fcd8f1
'''
이와 같은 설치시 내부 네트워크 조작등 가장 강력하게 테스트를 해볼수 있다. 다만 큰 메모리에 하이퍼바이저를 구하기가 쉽지 않을 수 있다. 현재로서는 gce에서 요새 nested-virtualization 을 지원하는 vm을 만들 수 있어서 이곳이 가장 용의 할 것 같다.
gcp
구글 클라우드 플랫폼은 설정만 다 되면 쓰기에 좋은 편이다. 현재 커널 4.14.x가 동작하지 않는것만 알면 우선 작동이 어렵진 않다. 다만 작은 문제들이 있는데 예를 들면 다음과 같다.
-
linuxkit에서는 현재 이미지이름과 같은 vm을 생성한다. gcp에서는 호스트네임이 유니크 해야되서 이때문에 node들은 일부러 이미지를 이름을 다르게 해서 올려야 한다. 예를 들어 아래처럼 01 02 03 과 같이 이름을 다르게 써야 한다.
linuxkit push gcp -project alproj -bucket linuxkital \ -img-name cilium-kube-node01 cilium-kube-node.img.tar.gz linuxkit run gcp -project alproj -keys 'key.json' \ -zone asia-east1-c -machine n1-standard-2 -disk 10 cilium-kube-node01 linuxkit push gcp -project alproj -bucket linuxkital \ -img-name cilium-kube-node02 cilium-kube-node.img.tar.gz linuxkit run gcp -project alproj -keys 'key.json' \ -zone asia-east1-c -machine n1-standard-2 -disk 10 cilium-kube-node02``
-
생성할때 disk를 추가해 줘야 한다. 이건 문제라기 보단 당연한 건데 gcp, aws들은 이미지를 raw타입을 쓰고 이미지의 사이즈에서 resize(extend 하지 않으면 디스크 사이즈가 아예 없다고 봐도 된다. 그래서 추가디스크(eg. sdb)로 용량을 확보(eg. docker image가 저장되는 /var/lib 등)해서 사용 할 수 있다.
-
metadata를 linuxkit command로 넣을 수 없다.. 아직 기능부족으로 문제가 된다. 수동으로
kubeadm join커맨드를 돌려서 작동 시킬 수 있다. 하지만kubeadm join커맨드를 돌리면/etc/kubernetes/bootstrap-kubelet.conf만 생성된다. 원래 kubelet이 떠있으면 이 파일이 생성되면서 자동으로 kubelet이 이파일로 노드 등록을 하게 되나 linuxkit은 kubelet service가 systemd 등과 같은 툴로 실패해도 지속적으로 구동되도록 트라이 하지 못함으로 특정 파일이 생길때까지 wait을 해놓은 상태이다. 그래서 특정 파일을 생성해 줘야 kubelet 서비스가 뜰 수 있다. 이걸 코드로 표현 하면 다음과 같다.
kubeadm join 10.140.0.2:6443 \
--ignore-preflight-errors=all \
--token gitpj4.gtok7zsm3tfrlh64 \
--discovery-token-ca-cert-hash sha256:773e83472b9809473cde237246227dfc2cd795a5848f127de11b3a5fb6550fb9
touch /etc/kubernetes/kubelet.conf
aws
aws는 결론만 놓고 이야기 했을때 현재 성공하지 못했다. 마지막으로 확인한것은 모든 network acl을 풀었으나 kubelet 노드의 apiserver에 대한 request들이 실패하는 로그들과 함께 실패했다. 다만 4.14.x 대역의 커널도 지원하고 있어서 삽질을 더 하면 사용가능 할 듯 하다. 여기도 추가적인 문제점은 다음과 같다.
-
image의 overwrite가 안된다. 옵션으로 풀수 있을지 모르지만 AMI를 등록 취소시키고 다시 하는 방법만으로 사용했다.
-
gcp와 같이 디스크 추가가 반듯이 필요하다.
-
metadata도 현재 사용 불가능 하다.
사용가능한 네트워크 구조들
weave
weave는 아무런 준비없이 사용하기 좋은 터널링 네트워크이다. 다만 현재 4.14.39 커널까지는 vxlan interface에 문제가 있어서 멀티노드로 띄울 시 문제가 있다. 그래서 현재 패치를 제출한 상태인데 아직 머지는 안된 상태이다. 커널을 4.14.40 이상이면 vxlan 문제는 해결 된다.
calico
calico는 역시 weave 다음으로 설정이 간단하다. 다만 weave와 달리 calico 부터는 네트워크의 메터데이터 저장이 필요하고 이 때문에 etcd 혹은 K8S Custom resource definition가 필요하다. 이 때문에 모든 노드에서 접근 가능한 etcd 설정이 필요하다. 하지만 kubeadm으로 설정시 아직은 127.0.0.1과 같이 etcd가 설치되기때문에 멀티노드에서 접근 가능한 etcd가 미리 준비되어야 한다. 이걸 staticpod으로 생성시켜 kubeadm 에서 생성되지 않고 bypass 하도록 구성시켜야 한다. 이후엔 메모리도 적은 간편하고 성능 좋은 네트워크를 갖을 수 있다.
cilium
cilium은 eBPF를 구동시켜보고 싶은 분들에게는 아주 희망적이고 간단한 테스트 방법이 될거라고 생각한다. 다만 노드당 4G이상의 메모리가 필요하다는것 그리고 cilium의 docker 이미지가 ubuntu base 이기 때문에 alpine base 의 이미지의 바이너리가 필요하다. 왜냐하면 이 바이너리를 cilium-node에서 node로 복사해서 해당 cni를 사용할 수 있게 해주기 때문이다. 또한 etcd가 필요하기에 etcd를 멀티노드에서 접근 가능한 방법으로 구성해야 한다.
demo
linuxkit + kubernetes + cilium을 mac에서 테스트한 것 입니다.

마지막으로
사실 아직까지 production에 사용하는 것은 여러가지로 한계들이 충분히 있습니다. 왜냐하면 저희가 가지고 있는 환경들도 제약적인 부분들이 많기에 힘든부분들이 많다고 생각합니다. 하지만 조금더 후엔 기존에 rpm으로 kubernetes package가 나오는것들이 이런 이미지 형태로 kubernetes 에서 제공될것이라고 생각합니다. 그때에서도 이런 부분들이 충분히 실험적일 수도 있지만 인프라가 가야하는 방향중에 한가지라고 생각하기에 제가 한달간 조사하고 삽질 한것을 많은 분들게 공유하려고 정리 했습니다.
개인적으로 기존 제가 테스트 할때 사용하는 클러스터는 이런 방식으로 전환해서 사용하려고 계획하고 있습니다. 사용하면 할 수록 매력적인 부분들이 있는것 같네요. 다른 분들도 이런 즐거움을 느낄 수 있었으면 좋겠습니다.